Introduction to BioMart
Ensembl BioMart is a powerful web tool (with API) for performing complex querying and filtering of the various Ensembl databases (Ensembl Genes, Mouse Strains, Ensembl Variation, and Ensembl Regulation). It is often used for ID mapping and feature extraction. Almost any data that is viewable in the Ensembl genome browser can be accessed systematically from BioMart.
Browsing
To browse Ensembl BioMart you can simply navigate to the main page directly, by google or from any Ensembl page.
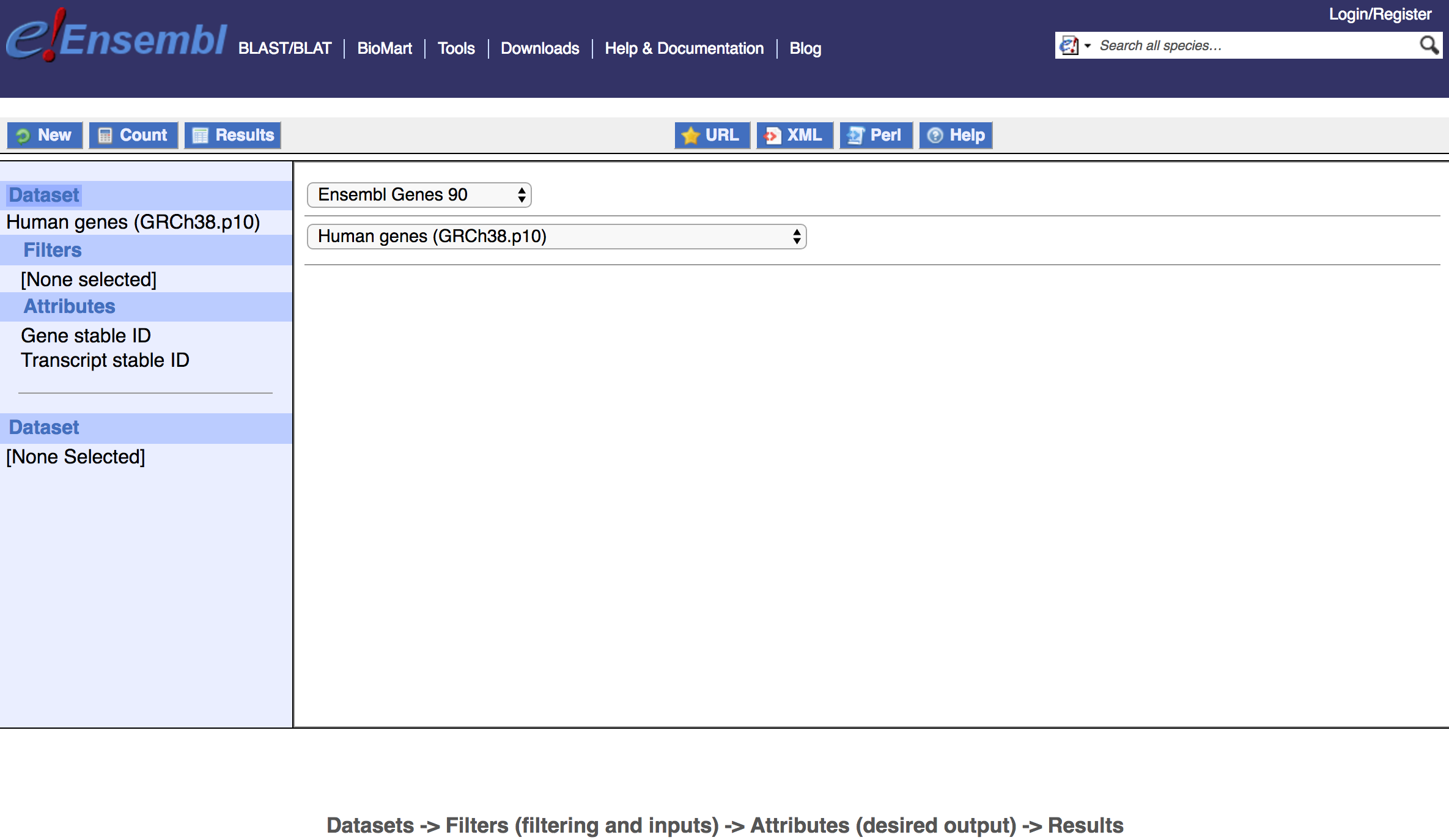
To do anything, you will first need to select a database from the CHOOSE DATABASE menu. Currently, this can be any of: Ensembl Genes, Mouse Strains, Ensembl Variation, or Ensembl Regulation. Note, the database version is included in the name (e.g., Ensembl Genes 95). The Ensembl Genes dataset is probably the most commonly desired choice, depending on your purpose. Next, you will select a dataset from the CHOOSE DATASET menu, which for Genes means selecting a species (e.g., Human genes (GRCh38.p10)). For illustration, we will walk through some examples using the Ensembl Genes 95 database and Human genes dataset. Once a database and dataset have been selected, you have the option to apply Filters and desired Attributes from the left panel. Note that two attributes (Gene stable ID and Transcript stable ID) have been pre-selected for us.
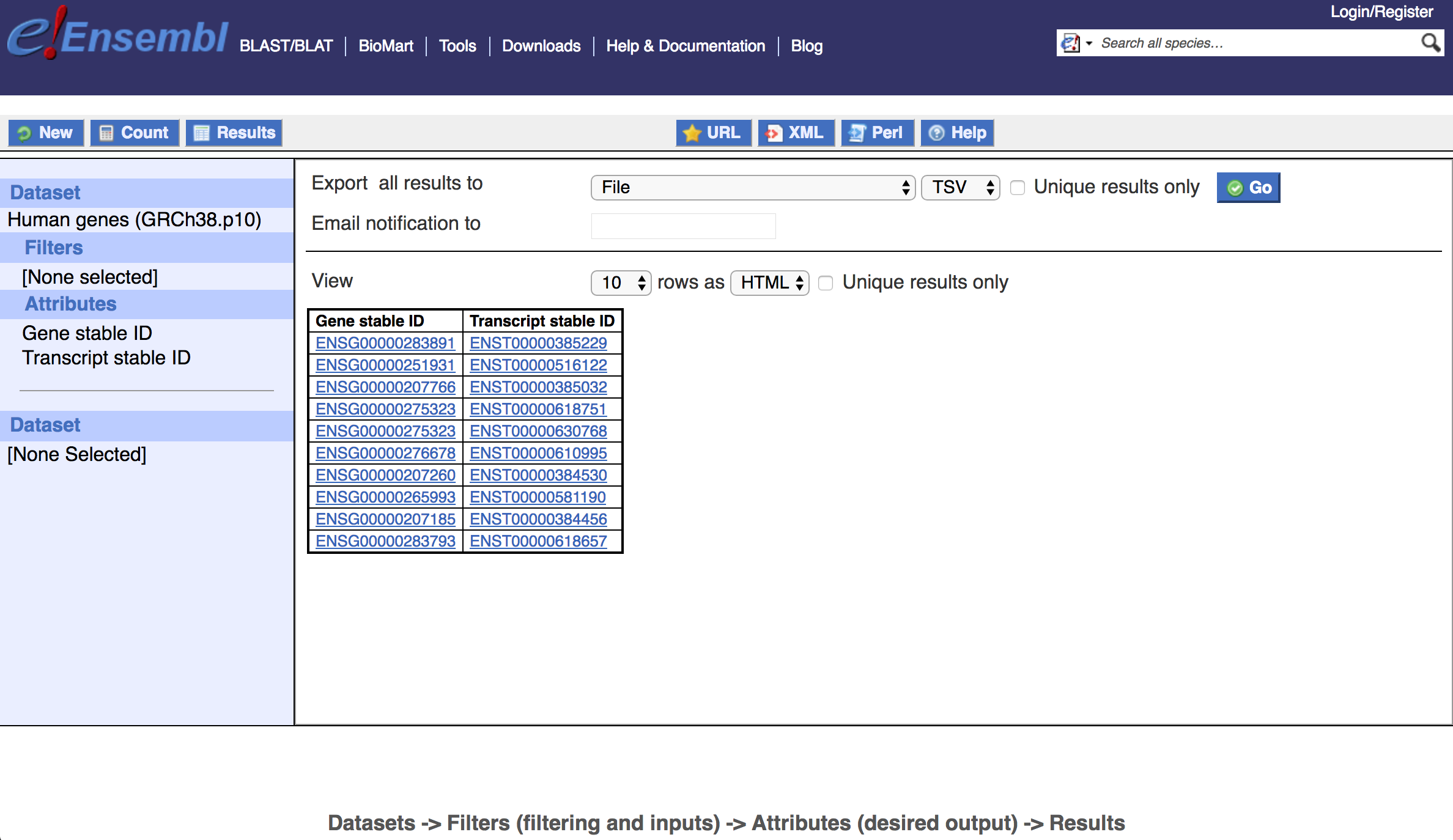
If we were to select Results now you would get the complete Gene and Transcript stable IDs for all genes in the Human Ensembl Genes (v95) database (see below). By default, 10 rows of results in HTML format (including hyperlinks to Ensembl pages) are shown. Selecting Count would give us a numerical summary of all records. In this case there are 63,967 results (Ensembl genes) available. We have the option to view or export in HTML or plain text (TSV or CSV) and also to export as XLS. Depending on what attributes are selected for display, there may be redundant results. For example, if we ask for only HGNC symbol as an attribute, BioMart will return the symbol for every Ensembl gene. Some Ensembl genes have the same HGNC symbol. Selecting Unique results only will filter out any redundant result rows from the display or exported file. Selecting New would reset our BioMart query.
Basic Filtering
The Filters option (left panel) allows for very powerful filtering. Again, using the Human Genes database/dataset as an example, this allows filtering of human Ensembl genes (and their attributes) by: Region, Gene, Phenotype, Gene Ontology, Multi Species Comparisons, Protein Domains and Families, and Variants. For example, suppose that we want to determine all of the genes on chromosome 17 between positions 39,600,000 and 39,800,000. We can specify a filter with Chromosome/scaffold=17, Coordinates Start=39600000 and End=39800000 (Note: do not include commas in the coordinates). For Attributes we might specify Gene stable ID, HGNC symbol, Chromosome/scaffold name, Gene start (bp), and Gene end (bp). The last three will help us verify that BioMart is returning genes in the requested region.
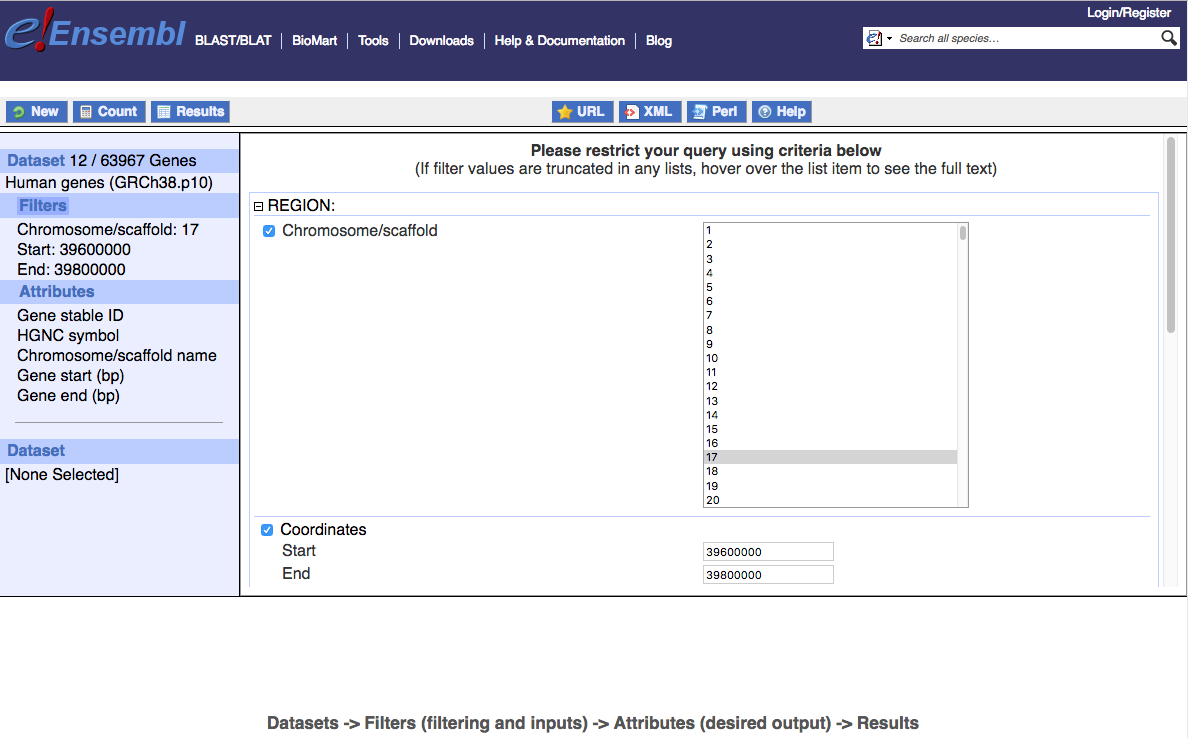
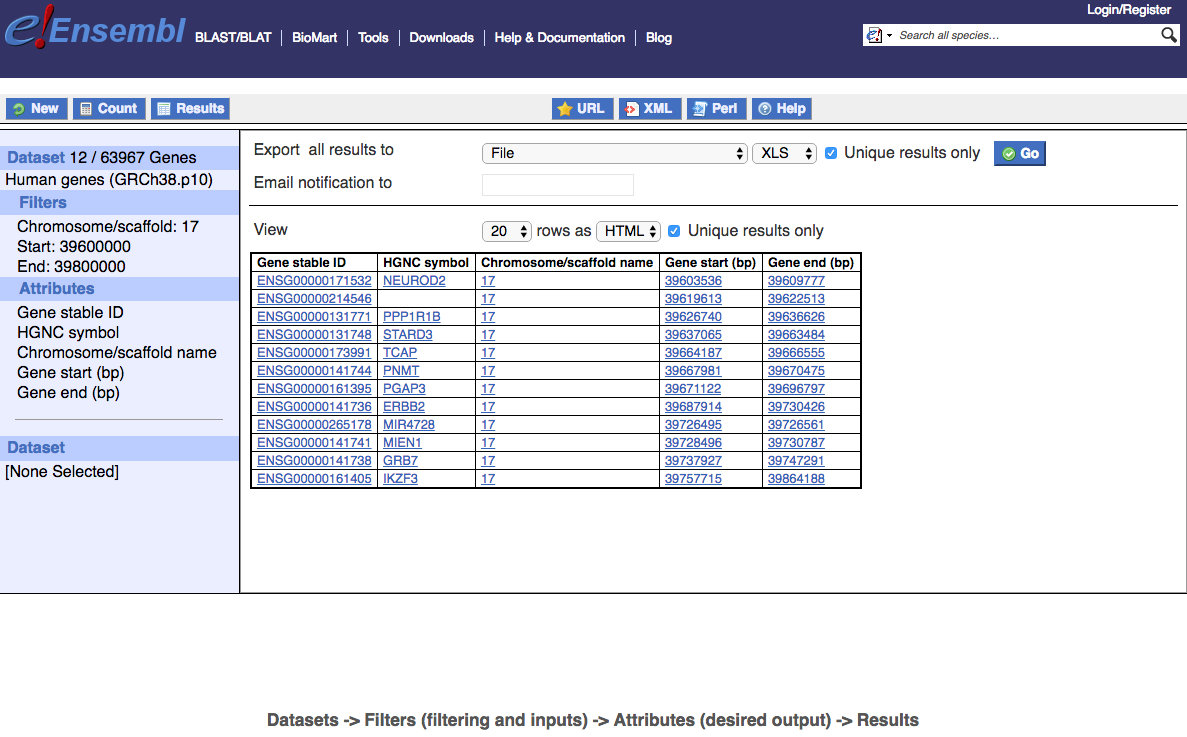
By selecting Count and then Results, limiting to Unique results only and increasing the View to 20, we can see that there are 12 Ensembl genes in this region, including 11 with HGNC symbols. This region includes the genes commonly amplified in HER2+ (ERBB2+) breast cancer. Note that one gene (IKZF3) starts within the filter region but its Gene end extends beyond it. This tells us something important about how BioMart applies coordinate filtering. If we wanted only genes entirely contained within the region we would need to apply our own additional filters.
Gene ID Mapping
Another very common use of BioMart is for gene ID mapping. In the Gene section of Filters it is possible to limit to only Ensembl genes that have at least one associated external gene ID or microarray probe(set) from a specific source. A very large number of such external gene ID sources (e.g., CCDS, Entrez, GO, HGNC, LRG, RefSeq, Unigene, etc) or microarray platforms (e.g., Affymetrix, Agilent, Illumina) are available. It is also possible to input a list of individual external IDs or probe(set) IDs of interest and get back the matching Ensembl gene records. For example, lets suppose that we had the list of HGNC gene symbols for the HER2-amplified region mentioned above (NEUROD2, PPP1R1B, STARD3, TCAP, PNMT, PGAP3, ERBB2, MIR4728, MIEN1, GRB7, IKZF3) and we wanted to know the corresponding Ensembl gene records and relevant attributes. Create a New query and again select the Ensembl Genes 95 database and Human genes dataset. Go to Filters -> GENE, check Input external references ID list, select HGNC symbol(s) and enter the above genes in the box (one per line). Now go to Attributes -> Features and choose GENE: Ensembl - Gene stable ID, Chromosome, Gene start, Gene end, Gene name; EXTERNAL: External References - HGNC symbol; Select Results. We now have direct mapping of HGNC symbols to Ensembl Gene IDs and associated attributes.
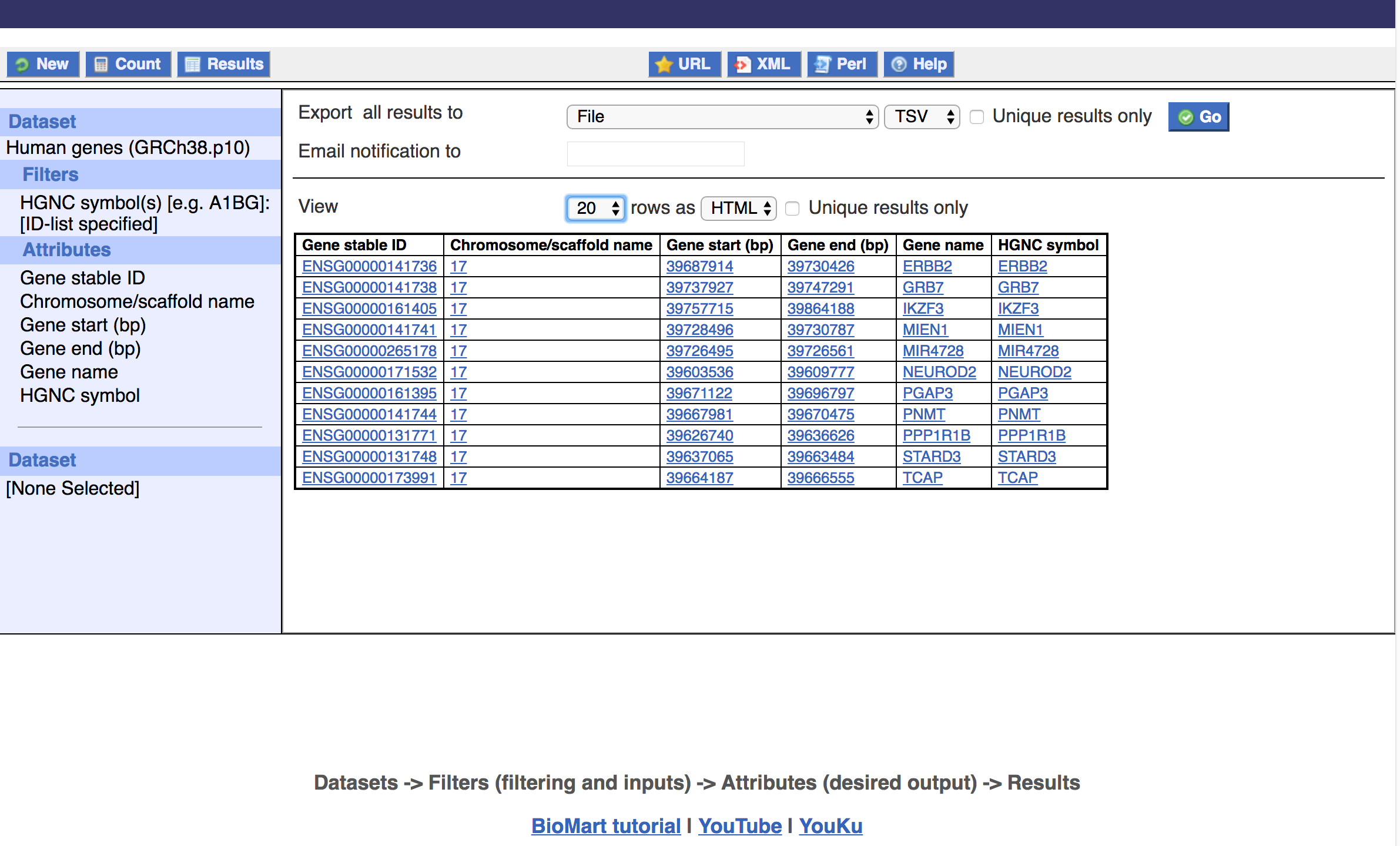
Note: It is important to remember that this procedure for mapping only works for genes that are represented as Ensembl gene annotations and is also dependent on their internal mapping between identifiers. It is possible that a valid protein might exist in another system (e.g., UniProt) and might have a valid link to another system (e.g., Entrez Gene) according to some (Entrez or UniProt) mapping process. But, if this gene was not successfully annotated in Ensembl or not successfully linked to both of these identifiers then it would be impossible to use BioMart to map from one to the other. Gene ID mapping is complex with multiple types of underlying analysis (methods for sequence or coordinate comparison) to determine equivalence and there may be one-to-many or many-to-many relationships. Ensembl and BioMart provide a valuable tool for dealing with this problem. However edge cases exist where it may not suit your purpose. It is always a good idea to determine which genes have failed to map and determine whether this is acceptable to you.
Also note: In the above query we asked for both the Ensembl Gene name and HGNC symbol. In many cases these are the same but not always. In some cases where an HGNC symbol has not yet (or recently) been assigned, Ensembl may choose another source or convention for its Gene name.
Getting Sequence Attributes
Another powerful application of BioMart is for the retrieval of Sequence attributes for specific genes or transcripts. Suppose that we would like all peptide sequences for protein-coding transcripts of TP53. Create a New query and again select the Ensembl Genes 95 database and Human genes dataset. Go to Filters -> GENE, check Input external references ID list, select HGNC symbol(s) and enter TP53 in the box. Also, select Transcript type = protein_coding. Now go to Attributes -> Sequences and choose SEQUENCES: Sequences - Peptide; HEADER INFORMATION: Gene Information - Gene stable ID, Gene name, UniProtKB/Swiss-Prot ID; Transcript Information - Transcript stable ID, Protein stable ID, Transcript type; Select Results.
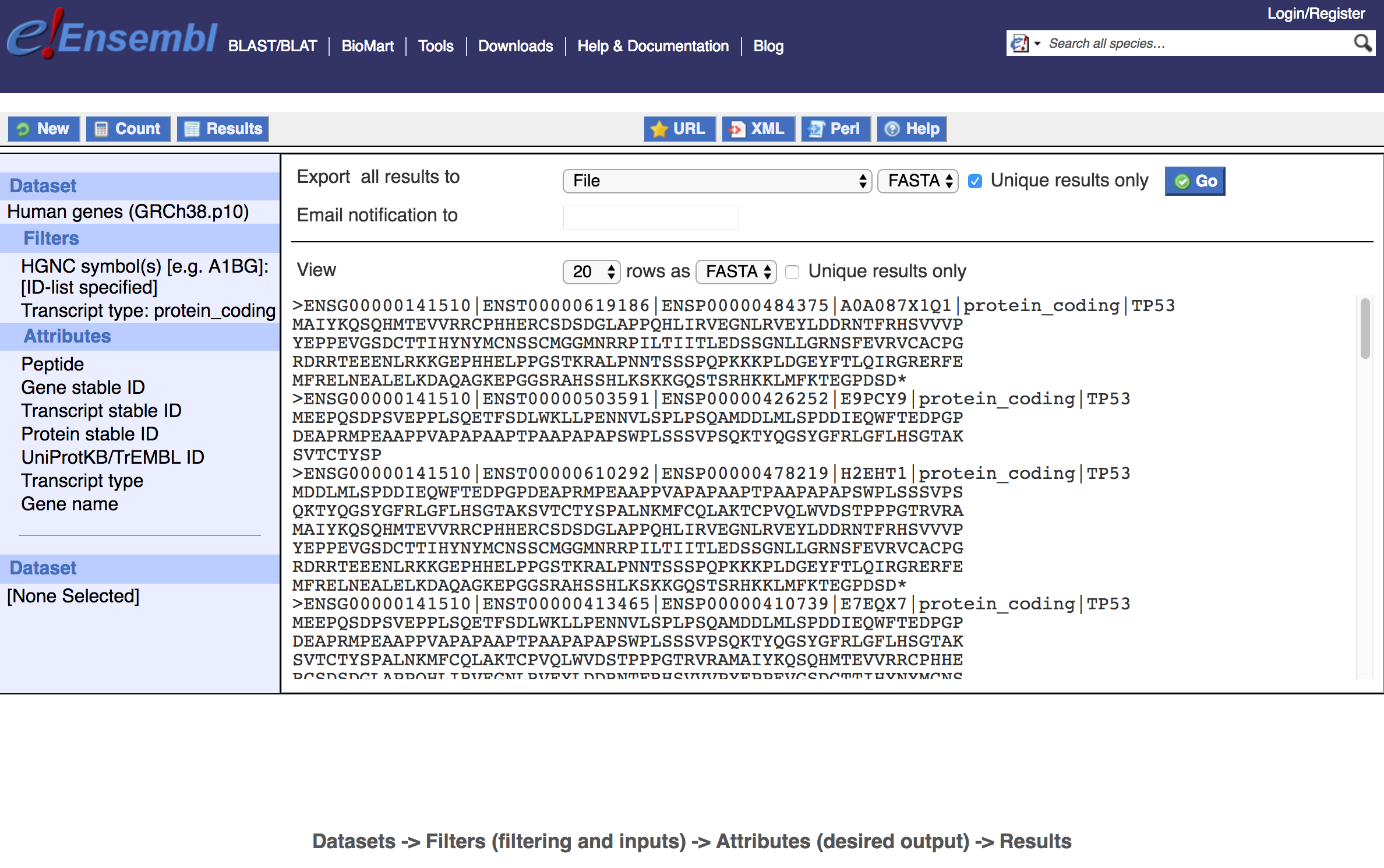
Here (above) we see peptide sequences in fasta format for all protein-coding Ensembl transcripts. Where available, the UniProt ID is listed along with Ensembl gene name, and gene, transcript, and protein ids. Download the fasta file by selecting Export all results, File, FASTA, Unique results only, and Go. Open the file in a text editor/viewer. Note that for some transcripts the peptides do not start with a methionine (e.g., ENST00000576024) or end with a stop codon (e.g., ENST00000503591). In some cases these transcripts are predictions from the Ensembl automated annotation pipeline and have limited biological evidence or support.
Ensembl BioMart practice exercises
How many transcripts are there (in Human Ensembl v95) for the gene TP53 that are: (A) protein-coding; (B) supported by at least one non-suspect mRNA (Transcript Support Level = TSL:1); but (C) have peptide sequences that still do not have a proper start or stop codon?
Get a hint!
To learn more about Ensembl Transcript Support Levels you can read their definitions in the Ensembl Glossary or review the transcript table for TP53.
Get a hint!
Sometimes, two queries are required to get a specific answer from BioMart. In this case you have been asked to limit to only transcripts with a certain Transcript support level (TSL). Unfortunately, this is not available under Filters. However, it is available under Attributes. Also note, Ensembl Transcript IDs can be used as a filter with the Filters -> GENE -> Input external references ID list.
Answer
There are is one TP53 transcript with TSL1 that does not have a start (ENST00000576024) and another that does not have a stop codon(ENST00000514944).
Solution
Create a New query and select the Ensembl Genes 95 database and Human genes dataset. Go to Filters -> GENE, check Input external references ID list, select HGNC symbol(s) and enter TP53 in the box. Also, select Transcript type = protein_coding. Select Attributes -> Features and choose GENE: Ensembl - Transcript stable ID and Transcript support level (TSL). Export the results to file (e.g., XLS), open in Excel (or similar), sort on TSL, and extract the Ensembl Transcript IDs for all tsl1 transcripts. Start a new query. Go to Filters -> GENE, check Input external references ID list, select Transcript stable ID(s) and enter the list of Ensembl transcripts from above in the box. Now go to Attributes -> Sequences and choose SEQUENCES: Sequences - Peptide; HEADER INFORMATION: Gene Information - Gene stable ID, Gene name, UniProtKB/Swiss-Prot ID; Transcript Information - Transcript stable ID, Protein stable ID, Transcript type; Select Results. Look for peptide sequences that do not start with M or end with a stop.
Using older versions of Ensembl BioMart
By default, Ensembl BioMart only presents data for the latest, most current version of Ensembl. Older versions can be accessed by navigating to an Ensembl Archive Site (linked from the bottom right of every Ensembl page) and then following the BioMart link (top left of every Ensembl Archive page). For example, the last version of Ensembl for the human GRCh37 (hg19) build was v75 (February 2014). The Archive EnsEMBL release 75 was available at http://feb2014.archive.ensembl.org and the corresponding BioMart at http://feb2014.archive.ensembl.org/biomart/martview.
Using the Ensembl BioMart API in R
In some cases it may be desirable to obtain data from Ensembl programmatically. This can be done in several ways. First, entire databases can be downloaded from the Ensembl FTP site in a variety of formats, from flat files to MySQL dumps. Second, Ensembl provides direct access to their databases via APIs. There are two main options: (1) the Ensembl Perl API; and (2) the Ensembl REST API. The Perl API has a longer history of use, supports many legacy scripts, and might be more comprehensive in terms of the number and complexity of queries it enables. It also supports any database version currently hosted on the web or locally installed. The REST API is more modern and allows you access to Ensembl data using any programming language. However, it appears to support only the most current database version (and version 75 for the human GRCh37 assembly). Finally, Ensembl BioMart also provides APIs for programmatic access. Again, there are several options including: (1) The BioMart Perl API; (2) BioMart RESTful access (via Perl and wget); and (3) The BiomaRt Bioconductor R package. The first two options are convenient because for any query you have configured in the BioMart website, you may simply select the Perl or XML buttons and you will have all of the code needed to execute a Perl API or RESTful API request via the command line. However, for those working in R or with less linux/Perl experience, the R Bioconductor may be preferred. We will demonstrate this final option here.
For illustration, we will recreate the Gene ID Mapping example from above. In RStudio or at an R prompt, execute the following commands:
# Install and load the BioMart library
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("biomaRt", version = "3.8")
library("biomaRt")
# Output all available databases for use from BioMart
databases <- listEnsembl()
databases
# Output all available datasets for the "Ensembl Genes" database
ensembl <- useEnsembl(biomart="ensembl")
datasets <- listDatasets(ensembl)
datasets
# Connect to the live Ensembl Gene Human dataset
ensembl <- useEnsembl(biomart="ensembl", dataset="hsapiens_gene_ensembl")
# Output all attributes to see which are available and how they are named
attributes <- listAttributes(ensembl)
attributes
# Output all filters to see which are available and how they are named
filters <- listFilters(ensembl)
filters
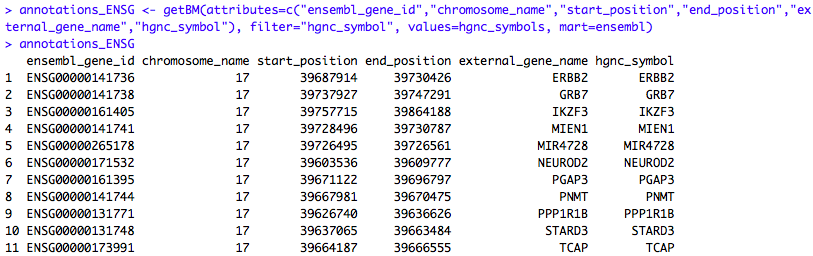
# Get Ensembl gene records and relevant attributes for a list of HGNC symbols
hgnc_symbols <- c("NEUROD2", "PPP1R1B", "STARD3", "TCAP", "PNMT", "PGAP3", "ERBB2", "MIR4728", "MIEN1", "GRB7", "IKZF3")
attributes <- c("ensembl_gene_id","chromosome_name","start_position","end_position","external_gene_name","hgnc_symbol")
annotations_ENSG <- getBM(attributes=attributes, filter="hgnc_symbol", values=hgnc_symbols, mart=ensembl)
annotations_ENSG
Note that the output is identical to what we retrieved earlier from the BioMart web interface. This is just a simple illustration of how (arbitrarily complex) Ensembl BioMart queries can be incorporated into an R script for analysis, visualization and interpretation.